二进制总结
简介
这一篇博客会把二进制利用的知识串起来,同时穿插pwn.college和其他CTF的题解,帮助自己理解和巩固。
内容会随着博主掌握的内容而更新,目前刚开始堆的基础部分
当然博主也是新手,有写错的地方勿怪
(声明:这篇博客所有记录默认是以64位架构为前提)
栈
栈结构与函数调用
首先个人觉得做二进制的题目,最基本的是需要了解栈结构。
栈的内存空间是从高地址向低地址增长,也就是说,每当有东西进栈,rsp将会-1,每当有东西出栈,rsp将会+1
每个函数在调用的过程中会维护自己的一块在栈上的内存空间,被称为栈帧;
函数在被调用时,首先会进行传参,但是否传入栈上,得看架构和参数个数;比如根据64位系统调用约定,前6个参数依次从rdi、rsi、rdx、rcx、r8、r9中读取,返回值保存在rax中。因此当参数个数超过6个,才通过栈传参(当然32位就是全用栈传参)
传参完成后会将下一条指令的地址压栈,即push rip,该地址被称为返回地址,这个动作由call指令自动完成
接下来会进入函数的所谓“序言”部分,即执行:压rbp入栈(push rbp)->把rsp的值赋给rbp(mov rbp,rsp)->rsp向低地址移动(sub rsp)
(备注:后续回顾时重点理解函数被调用时的进栈流程,和leave ret对应起来理解)
此时,函数的栈帧已经形成,栈的最高处是调用者的rbp,最低处是rsp,函数运行时的局部变量存在栈帧的靠近低处
从rbp到局部变量,中间的内容需要具体分析,可能会有canary等数据
综上,可以画出栈的一个示意图如下: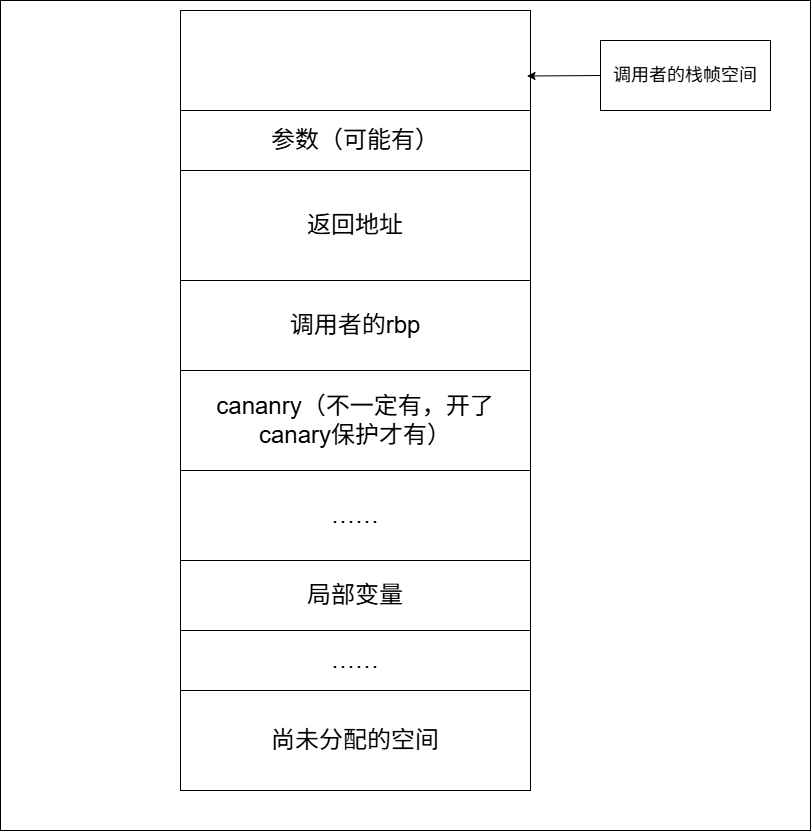
函数调用结束后,一般末尾会有leave和ret指令,这两条指令的等价形式如下:
leave=mov rsp,rbp;pop rbp,ret =pop rip
此时可以发现,这些操作正好对应着函数序言,即可以理解为序言的反操作,这也就是为什么函数在调用过后还能回到原来的地方继续执行(返回地址实现),同时调用者的栈帧也能恢复(rbp的入栈出栈实现)
缓冲区溢出攻击原理
分析上述栈结构和函数调用过程,可以发现局部变量(用户输入的缓冲区)是在返回地址下方,而用户输入是不可控的,如果没有长度校验,可以通过构造过长的输入去覆盖返回地址,从而劫持函数的执行流
当然,不一定所有题目都是覆盖返回地址,但目前遇到的还是以控制流劫持类型居多,因此主要记录这种;其他方法的例题本片文章也有收录,如覆盖关键校验值
最后一个问题:返回地址应该覆盖为什么?根据目前做题经验,总结为以下2类:
后门函数的地址
后门函数在题目中一般表现为可以读取、输出flag的函数,或者是直接调用system()等可以获得shell的函数
如果给的二进制文件中存在这类函数(通过逆向等手段发现),可以优先考虑覆盖返回地址为该函数的地址
shellcode的起始地址
shellcode即可以帮助攻击者获取shell的代码,当二进制文件本身不存在后门函数的时候,就需要攻击者自己编写shellcode(或重用程序已有的代码段),并将其溢出到程序内存中(可以是栈、.bss段、数据段等)
具体实现方法为通过编写汇编语言代码,调用system、execve等函数开启shell。由于python强大的pwn包,现在可以直接使用该模块生成一般的shellcode
溢出攻击的防御手段与克制方法
目前博主在做题当中遇到的主要会阻碍我们的防御手段就是以下3种(后面遇到了别的再记录):
NX保护
NX保护即指定栈不可执行,该保护主要用于防御直接往栈上写shellcode的攻击方式
为了克制NX保护,目前学到的有以下2种方法:ROP和mprotect函数
克制NX保护——ROP攻击
当开启了NX保护,栈上的数据将不可以被视作代码来执行,因此直接写shellcode行不通
那该怎么办?很简单,自己写的不让执行,那就用程序本身有的,毕竟一个程序,总是有可以执行的代码块的,不然写出来干啥呢?
但是,另一个问题,想要getshell用到的代码块可能散布在程序各个地址,不会老老实实连续(指物理上的连续)放在一起,所以只覆盖一个返回地址肯定不行
此时,注意到ret指令实质是pop rip,因此,只要找的每一块指令碎片都以ret或者pop rip或者其他可以修改rip的指令结尾,那这个片段就可以使用
因此,可以把ROP看成一种特殊的shellcode,这段shellcode和传统意义上的不同,物理上并不是连续存储在内存中,而是分散开来的指令碎片
每块碎片就像链表的结点,结点之间通过ret(或其他修改rip的指令)连接,通过这种方式,实现逻辑上好像执行了一段连续的shellcode,而攻击者要做的,就是把第一块指令碎片(表头)的地址覆盖到返回地址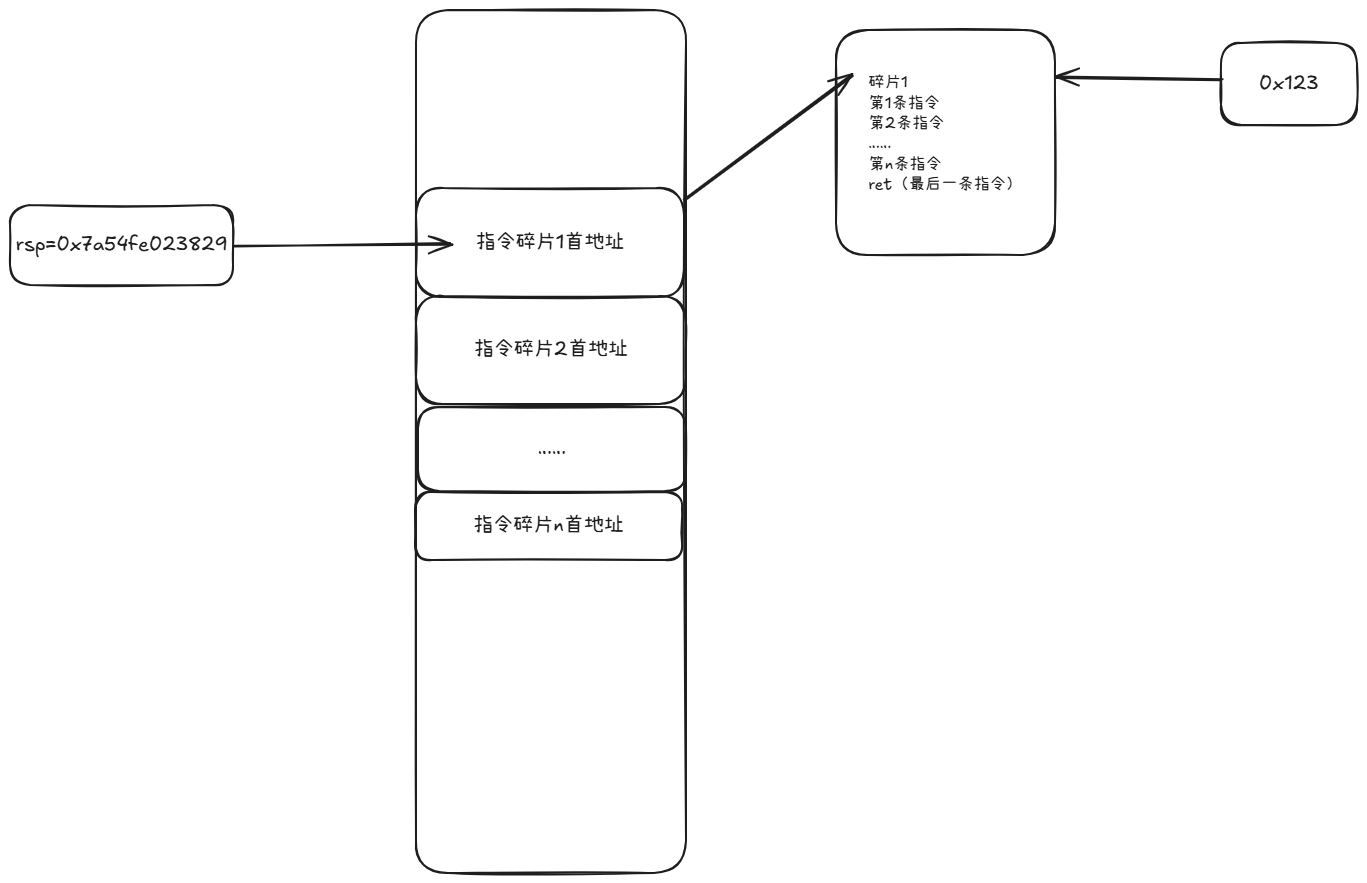
如上图,假设现在返回地址已经被覆盖为了第1块指令碎片的地址,并且函数下一条指令为ret
那么,一旦函数执行ret(即pop rip),会将rip的地址变成指令碎片的起始地址(即0x123,只是假设的地址,真正应该不会这么低),然后把rsp+1
因此rsp就会指向指令碎片2的地址,一旦碎片1执行完毕,由于最后一个指令是ret,同样会执行上述操作,从而rsp再指向碎片3的地址
……………………直到所有的指令碎片执行完毕,拿到shell
目前遇到的ROP题目大致分为两类:
第一是ret2text,即回到程序本身的代码段,该方法适用于程序自身的指令碎片比较丰富,有着大量可用的指令,如system、/bin/sh等,通过返回到这些指令的地址获得shell
第二是ret2libc,即回到libc中;因为一个动态链接程序(为减小可执行文件体积,现在大部分都是动态链接文件,如果遇到静态的,就又回到了第一种类型)在运行时会装载libc.so文件;
libc.so是一个共享文件(不准确的说,可以看成windows下的dll),这个文件里存储了大量的C库函数,因此这里面必定存在我们想要的system和”/bin/sh”字符串
但是,.so文件一定是PIE的,因此在ret2libc时,最关键的步骤是获取libc在装载时的基地址,最基本的思路是通过程序中调用的函数的got表泄露
再简单说一下got表和plt表以及Linux的延迟绑定机制
简单来说,程序在调用libc中的函数时,第一次调用时会解析该函数的真实地址并存储在got表里,后续第2次第3次调用时直接去got表拿地址,简单的示意图如下:
第一次调用时会进行如下流程
之后每次调用则如下图所示
因此,可以看出,只要泄露了某个函数的got表的地址,再减去其在libc里的偏移,即可得到其真实地址(只要给定libc版本,偏移就是确定的,可以通过readelf命令行工具或者python的pwn模块获取)
同时,从上面讨论可以看出,必须要泄露程序中被调用过的函数的got表,才能获得libc基址,因此个人常选择__libc_start_main函数,这是一个在启动main时必定会被调用的函数
ROP之栈跃迁
待补充……
SROP方法
- Linux信号机制:
信号可以简单理解为一种软中断,是进程之间传递信息的一种方式,在传递信号时大致过程如下图所示: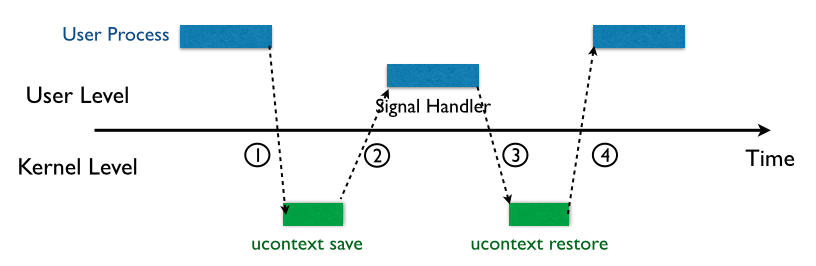
上图可以简单概括为以下步骤:
(1)用户进程接收到信号后,会陷入内核态,之后由内核为该进程保存上下文(可以简单理解为将所有寄存器压栈),之后会在 用户进程的栈上 构造一个叫做Signal Frame的结构体,如下图所示: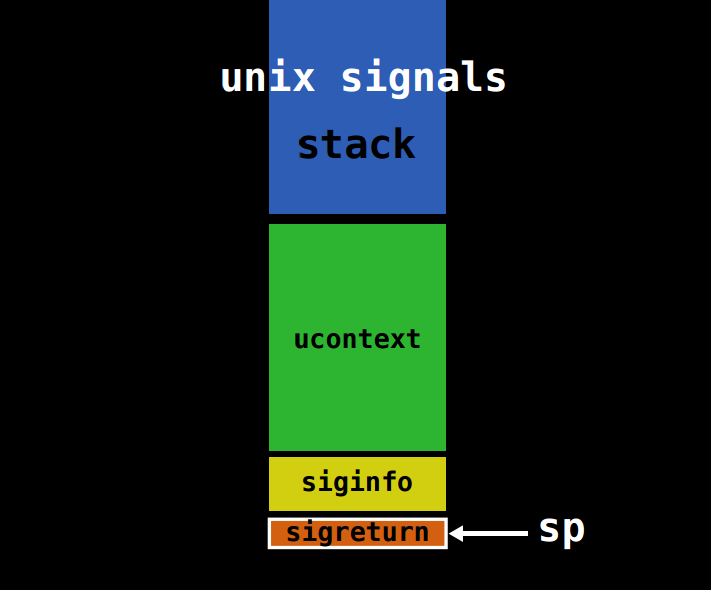
图中的uncontext和siginfo被称为Signal Frame,这里面保存了大量用户进程寄存器的值,并且该结构体保存在 用户进程的栈上 ,该结构体的具体定义在64位和32位下有所不同,分别如下:
64位:
1 | |
32位:
1 | |
(2)转向信号处理函数
(3)执行sigreturn,即上述栈视图的最底部,这是一个系统调用(x86_64下调用号=15,x64下调用号=77),会将保存的寄存器逐个pop回去,然后跳转到rip接着执行用户进程
2. 利用方法:
注意到上文在介绍Signal Frame的时候提到,这个结构体是保存在用户栈上的,因此如果能够溢出,则可以在栈上伪造一个Signal Frame(对应第一张图里的3号箭头,在restroe时欺骗内核恢复到假的寄存器值);
之后通过劫持程序控制流首先到sigreturn系统调用,在返回时最终执行rip里我们想要执行的shellcode(对应第一张图里的4号箭头,由于rip是假的,因此会从内核返回到假的地址)
例如,可以如下图所示,构造假的Signal Frame从而使得sigreturn返回时执行execve:
克制NX保护——mprotect函数
mprotect函数是C语言的一个用来修改内存区段权限的函数,该函数原型如下:
1 | |
其中,void* addr指向需要修改的内存段的起始地址;size_t len表示内存区段的长度(字节为单位)
prot表示期望赋予该内存段的权限,其中0表示无法访问,1表示可读,3表示可读可写,7表示可读可写且可执行
从上面的函数原型可以看出,通过mprotect函数可以将原本受到NX限制而不可执行的堆栈空间强行赋权为可执行
在实际使用中,还有以下2个小的注意点:
1 如何确定是否可以使用mprotect函数:当发现目标二进制文件是静态链接时,大概率会存在mprotect函数
2 mprotect的参数设置:mprotect函数标准规定,addr必须是一个内存页的起点,换句话说,addr的最后12位必须=全0;同时,len必须是页大小的整数倍,即k*4096;最后,在实际做题中,为保险起见,常赋予目标内存段最高权限,因此prot一般置为7
canary保护
canary即在rbp的下方放置一个随机数,并在安全位置保存该随机数的副本,退栈时比对副本和读取到的随机数,如果不一样说明发生了溢出攻击
克制canary保护
第一种方法是直接泄露canary的值,该方法需要程序本身有输出内存中的值的功能,或者攻击者能调用输出函数输出内存值
另一种方法是爆破:canary的第一个字节一定是0x00,这是为了截断字符串读取,防止canary泄露而设计,但这种设计也为canary的爆破提供了方便
只需要从第一个字节0x00开始,逐个字节的尝试,如果猜测正确,程序会正常执行,否则会出现异常(如输出”stack smashing detected”),最坏情况尝试256*7次,如下图所示
PIE保护
PIE全称为位置无关可执行文件,开启了这个保护的程序,每次运行时将被加载到不同的基地址,因此程序里所有的指令地址在运行前都无法确定
换句话说,通过objdump反汇编看到的指令地址、函数起始地址,都是偏移量,不能直接使用
克制PIE保护
尽管存在PIE,但由于操作系统需要页对齐,即每页大小4096字节,而4096正好=0x1000,因此返回地址的最后12位(或者说最后一个半字节是确定的)
由此,为了克制PIE,可以采取低字节部分覆盖的攻击方法,只覆盖最后两个字节,其中只有一个16位数不确定,因此尝试16次即可
综上,当实际做题时,首要步骤应该是使用checksec命令去检查程序的保护措施,如下图:
这个程序是保护全关,但是看到哪种保护开启了,其实也是变相在提示解题思路
比如看到NX就知道栈上写shellcode的方法肯定废了,应该要ROP,或者有后门函数?看到canary和PIE,想到要爆破,或者想办法泄露一个基地址?
其他琐碎知识点
C程序启动过程——重新认识main函数
做题时发现对程序的启动以及main函数的加载退出机制不是很了解,严重影响做题,遂做一下记录
首先,main并不是程序真正的起点,在main函数之前,需要由_start函数去调用__libc_start_main,_start并不是开发者写在代码里的一个函数,而是编译时生成
将任意一个ELF文件拖入IDA,可以看到_start函数内部的样子如图所示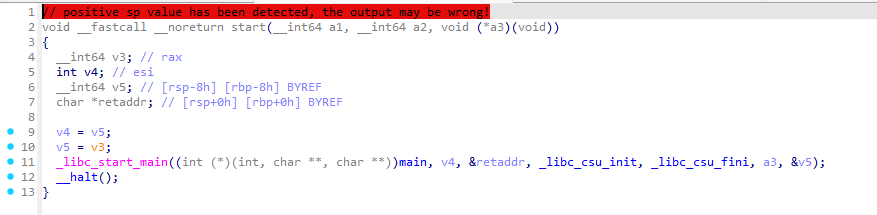
接下来说一下__libc_start_main,这是一个libc动态连接库(.so文件,即shared object)中的函数,它才是真正完成启动程序,设置寄存器值,调用main这一系列任务的函数
通过将.so文件拖到IDA里,同样能看到__libc_start_main如图所示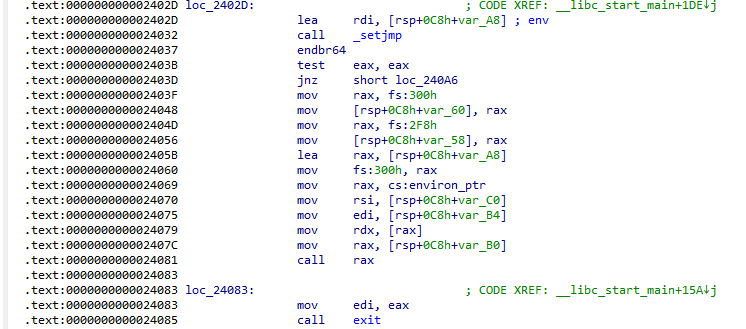
如上图,从0x2402D处开始,__libc_start_main在为main函数启动做一系列准备,最后,在call rax处真正启动main函数
接着梳理main函数的退出机制,即return 0;之后究竟做了什么
还是看到上图逆向libc.so的结果,可以在0x24083处看到这样的指令
1 | |
回想64位系统的调用约定和传参约定,这两条指令实际上说明,当main函数退出时,会把返回值(一般是0)作为exit的参数从rax传递给rdi。紧接着下一条指令调用exit
32位程序的传参问题
从栈结构与函数调用一节中可以得知,32位程序传参一定是通过栈进行,并且参数会被调用者布置在返回地址的上方
当调用者布置完参数后,会通过call指令调用目标函数,具体来说,call指令会做以下2件事:
1 push eip,即保存返回地址到栈上
2 jmp ,即根据call后面的地址,跳转到那里执行那里的代码块
从上面的call过程,可以看出,正常情况下,32位程序中的被调用函数,会从ebp+8位置开始寻找参数(因为ebp+4是约定好的返回地址,返回地址再往上一格才是参数),如下图所示:
这样一来,在实际做题时就要注意一下参数的布置了
因为做题时是通过溢出返回地址从而劫持控制流,导致跳转时相比正常的call,缺少了第一步——push eip,如下图所示: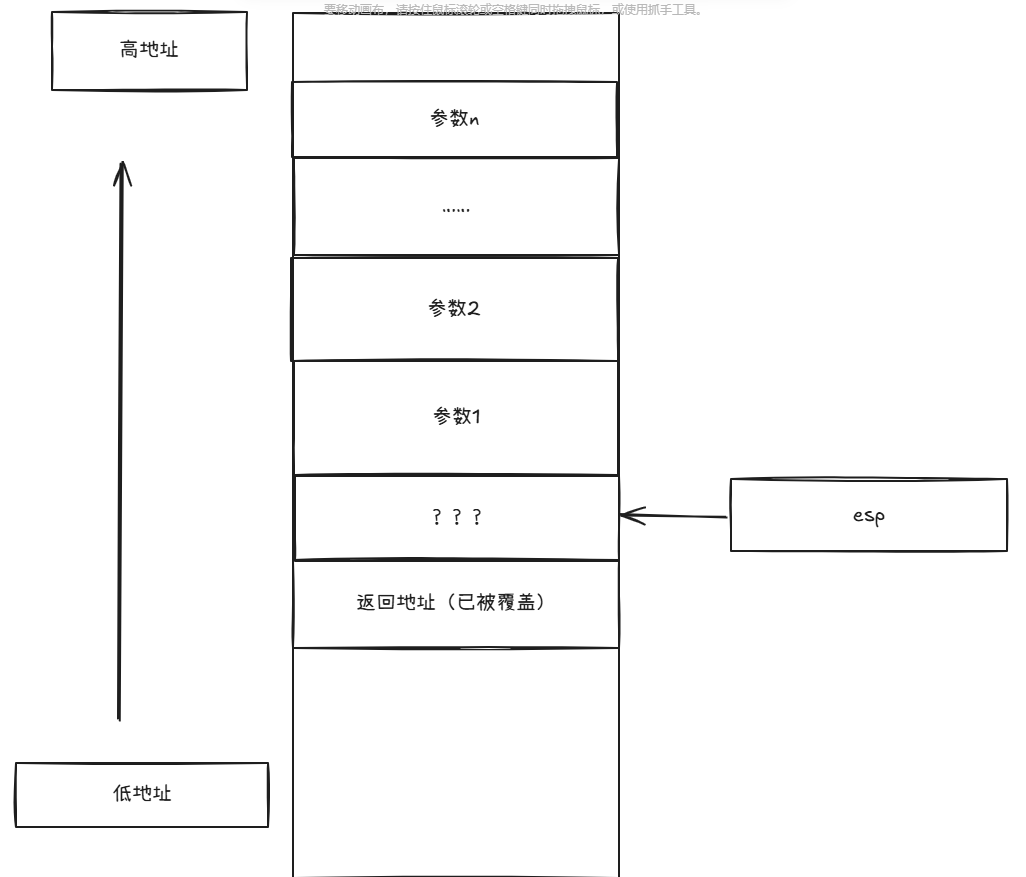
从上述两张栈布局示意图可以看到,当实现溢出时,如果在payload中直接将参数填在返回地址后面,比如:
1 | |
由于缺少一个push eip的操作,导致argc被布置在winAddr的上方(即上述第二张图的???位置),但cpu不管这些,他会误认为argc是返回地址,从而去argc上方4个字节处取参数,这就显然和预期的不符了
所以,正确的payload构造应该如下:
1 | |
即通过填入4个字节的垃圾数据,使得cpu能正确找到我们想要的参数
这是针对单阶段,如果在winAddr后面还想返回到别的函数怎么办?(常见于泄露libc基址,需要在第一阶段最后返回到main)
也很简单,只要把脏数据变成想要的地址即可(实质上等价于通过溢出实现push eip的操作),比如,泄露libc时:
1 | |
堆
在glibc中,通过一个叫做ptmalloc的东西去管理程序动态申请的内存,以下均以glibc的堆管理机制为前提
堆概述
回忆C语言的动态内存管理,如下:
1 | |
我们知道malloc返回给我们的是一个指针p,p指向内存中一块固定大小的区域,我们称这块区域和它的前面16个字节为chunk
首先必须提到堆的一个重要特性: 返回给我们的chunk的大小不一定等于申请的大小 (一般会更大),这也就是为什么上面没有说p指向的是一个chunk
那么为什么返回的chunk大小和申请的不一致,甚至要加上16字节呢?这主要是因为一个chunk除了存储用户数据,还需要存储一些元数据用于管理
具体chunk的结构示意参见下图: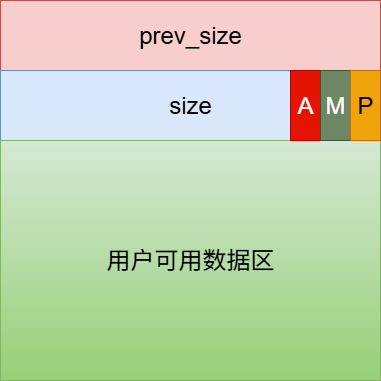
IO_FILE利用
glibc IO_FILE基础
待补充……
FSOP
调用链:_IO_flush_all_lockp ——> fflush ——> _IO_OVERFLOW
而在调用_IO_OVERFLOW时,具体实现是从vtable+0x18的位置取指针,然后去call这个地址
因此这里就存在攻击面,如果把_IO_list_all的指向修改为一个我们可控的内存段,我们就可以通过这个伪造的FILE结构体,触发任意函数
具体来说,这个结构体(IO_FILE)需要满足以下条件:
- IO_FILE._mode=0,即*(&IO_FILE+0xc0)=0
- IO_FILE._IO_write_ptr>IO_FILE._IO_write_base,常设置*(&IO_FILE+0x28)=1,*(&IO_FILE+0x20)=0
- IO_FILE.vtable=可控地址,即*(&IO_FILE+0xd8)=fakeVtable
House of Apple
回顾glibc的_IO_FILE(其实是_IO_FILE_complete)结构体,除了低版本下关注的vtable成员,其实还有一个重要的成员——_wide_data,如下:
1 | |
wide_data成员的结构如下:
1 | |
其中也存在一个vtable成员,而且针对该vtable的跳转即使在高版本中也是没有检查的,比如调用overflow,调用链如下:
1 | |
对比常规的_IO_file_jumps,可以看到在宏函数中引入了明显的validate检查:
1 | |
而House of Apple就是一种利用wide_data成员进行控制流劫持的方法,该手法需要满足以下几个条件:
- 能够泄露libc和堆地址(至少要libc)
- 能任意地址写到_IO_FILE的vtable和wide_data
- 能触发:exit、从main函数返回、触发abort
先记录第一种方法,该方法利用了如下的调用链:
*** _IO_wfile_overflow ——> _IO_wdoallocbuf ——> _IO_WDOALLOCATE ***
具体的源代码分别如下: - _IO_wfiel_overflow:
1 | |
- _IO_wdoallocbuf:
1 | |
最终会在_IO_WDOALLOCATE宏中去call相应的函数指针(其实是_wide_data->_wide_vtable+0x68处的函数指针)
回顾整个调用链,总结出需要让程序执行到最终的_wide_vtable+0x68,需要伪造的IO_FILE结构体满足以下条件:
- 首先满足前述的FSOP条件,确保程序能正常走到_IO_flush_all_lockp
- flag & 0x0008=0(一般填成0x68732020),即” sh”,因为system(“ sh”)即等价于sytem(“sh”)
- vtable设置为_IO_wfile_jumps,如果libc.symbols搜索不到符号,可以用_IO_file_jumps-0x540(实测好像和libc版本无关,基本都对)
- 将_wide_data字段设置为可控地址,具体即如下所示的模板片段:
1 | |
其中参数wide_data即为我们可控的地址,常常是一个堆地址
5. 将wide_data的vtable设置为一个可控地址,同时满足:
- wide_data->_IO_write_base=0
- wide_data->_IO_buf_base=0
构造模板如下:
1 | |
其中wide_data_vtable为可控的地址
6. 将伪造的vtable的doallocate函数指针设置为system,构造模板如下:
1 | |
题目实例
pwn.college——栈
劫持到后门函数
具体的题目实例见pwn.college题解:Control-Hijack
(备注:可以通过该题目了解最基本的栈溢出该怎么利用,以及各种工具的基本使用)
劫持到shellcode
具体的题目实例见pwn.college题解:Hijack-to-Shellcode
基础ROP
- ret2text:pwn.college题解:ROP-level3
- ret2libc:pwn.college题解:ROP-level4
克制PIE
具体的题目实例见pwn.college题解:PIEs-hard
克制canary
一些trick
消除shellcode的零字节
具体的题目实例见pwn.college题解:NULL-Free-Shellcode
绕过strlen长度限制——0x00字节填充
具体的题目实例见pwn.college题解:String-Lengths-hard
ROP之栈跃迁
具体的题目实例见pwn.college题解:ROP-level-9
其他刷题记录
ret2text技巧
- 32位程序,本身存在system和/bin/sh,直接return;具体的题目实例见BUUCTF题解:jarvisoj_level2
- 32位程序,存在多阶段后门函数,但要打包负数;具体的题目实例见BUUCTF题解:picoctf_2018_rop_chain
- 64位程序调用execve,需要布置3个参数,gadget里没有控制rdx的碎片,利用__libc_csu_init函数里的指令;具体的题目实例见BUUCTF题解:ciscn_2019_s_3
沙箱及其绕过
具体的题目实例见分类”pwn刷题记录/其他技巧类”下的文章:沙箱问题
ret2shellcode技巧
上述pwn.college的ret2shellcode仅是作为基础,其服务器并没有开启ASLR,导致可以直接硬编码栈地址为返回地址,而真实的CTF题目不会这么顺利,所以用2道题记录一下真正ret2shellcode时该怎么做
- 泄露栈地址:pwnable题解:01-start
- 无需(也无法)泄露栈地址,则控制rsp:BUUCTF题解:ciscn_2019_s_9
- 有时,即使开启了NX保护,依然可以使用shellcode解题,具体的题目实例见mprotect技巧
ret2libc相关
- printf泄露libc基址:具体的题目实例见BUUCTF题解:[HarekazeCTF2019]baby_rop2
- write泄露libc基址:具体的题目实例见BUUCTF题解:jarvisoj-level1
通过以上两道题,加上最常见的puts函数泄露,目前可以总结出三种泄露方法:即puts、printf和write - 无脑ret2libc的方法:具体的题目实例见分类”pwn刷题记录/其他技巧类”下的文章:部分题目的通解:ret2libc
非劫持类手法:覆盖关键变量绕过检查
在溢出中,并不一定是覆盖到返回地址从而劫持控制流,还可以通过覆盖上方变量来绕过校验
具体的题目实例见分类”pwn刷题记录/其他技巧类”下的文章:2025年7月26日shaktictf比赛题解:Amogus
整数溢出
整数溢出基础例题(由于pwn.college上暂时没找到整数溢出类题目,以一道BUUCTF的题目为例进行记录):BUUCTF题解:bjdctf_2020_babystack2
覆写GOT表技巧
做题时踩过的一些坑
堆栈平衡问题
堆栈平衡问题仅针对64位程序,要求栈16字节对齐(但是实际发现有的劫持到后门函数的题,还需要跳过后门函数开始处的操作rbp的若干条指令,以及需要在后门函数后正确返回)
16字节对齐是因为Ubuntu18以后引入了对XMM寄存器的操作,但后两者的原因目前还不是很清楚……
具体的例子见:Pwn的坑:堆栈平衡问题
特殊情况下IDA获取偏移导致出错
具体的例子见:Pwn的坑:不能只在IDA里看偏移
有时劫持到后门函数需要正常exit
具体的例子见:Pwn的坑:正常exit问题